
IR: Learning to Rank
Information Retrieval & Data Mining is a graduate-level CS module I pursued while studying abroad at University College London, in the Spring of 2017. Its coursework component (40%) consisted of the following team project, whose abstract I present below. The project included literature review; evaluation of popular Learning to Rank algorithms; and building a Logistic Regression classifier to train a ranking model, which is optimized for and evaluated against widely used evaluation metrics.
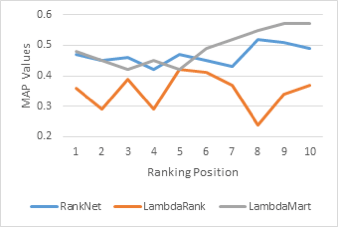
Learning to rank for Information Retrieval (IR) is a task to automatically construct a ranking model using training data, such that new objects can then be sorted according to degrees of relevance, preference, or importance. Learning to rank is useful for document retrieval, collaborative filtering, and many other applications. There are a huge number of IR problems that by nature are ranking problems, and can therefore be enhanced using Learning-to-rank techniques. In this paper, the three of the best algorithms for LTR are implemented and their performance compared by various metrics to determine each’s performance against the others. Analysis is performed on each of the approaches and advantages and disadvantages are discussed for each of the algorithms. We then train a learning to rank model to optimize a target evaluation measure with respect to the given training data. To assess these techniques, we work with the MSRDataset, provided by Microsoft.
Project Report: The full project report can be found here.
Github link: Learning to Rank
